目次
検証環境
- Windows 10 Pro 64bit (April 2018 Update)
- HTTrack(WinHTTrack) 64-bit 3.49.2
使おうと思った経緯
geocitiesが2019年3月末サービス終了
サービス終了のお知らせ - Yahoo!ジオシティーズ
…なのでgeocitiesのサイトで「自分のChrome内ブックマーク」「自分のURLショートカットファイル」「自分が登録したはてなブックマーク」「人気のはてなブックマーク」にある物から自分がチョイスした物だけでも保存しておこうと思いました
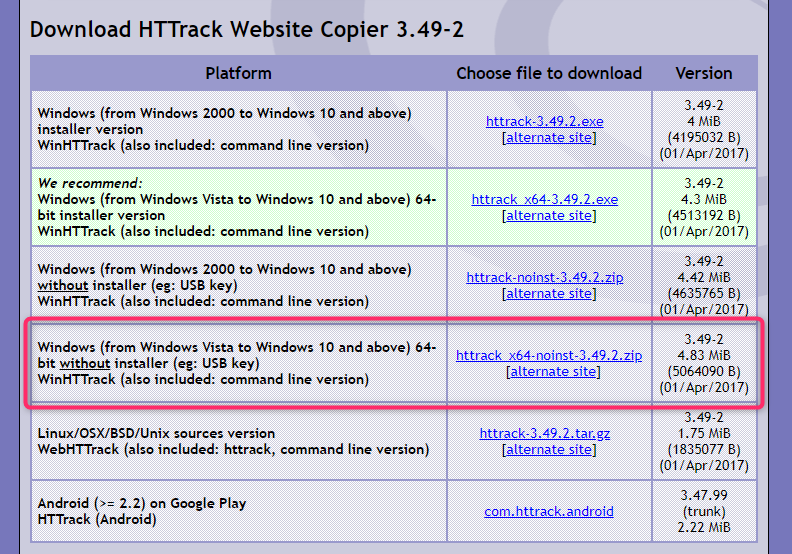
HTTrack(WinHTTrack) は以下の場所でダウンロードできます、私はzipの64bit版「httrack_x64-noinst-3.49.2.zip」を使っています
Download HTTrack Website Copier 3.49-2 - HTTrack Website Copier - Free Software Offline Browser (GNU GPL)
使用方法(雑雑雑)
取得前提
以下の前提で取得します
geocitiesにあるシンプルな静的ページという想定で、ちょっと凝ったページだと上手く取得できない可能性もありますが、それは仕方ないという事で割り切ります
- 指定したドメイン・フォルダ(とその下位ファイル・フォルダ)以外のファイルは取得しない様にする
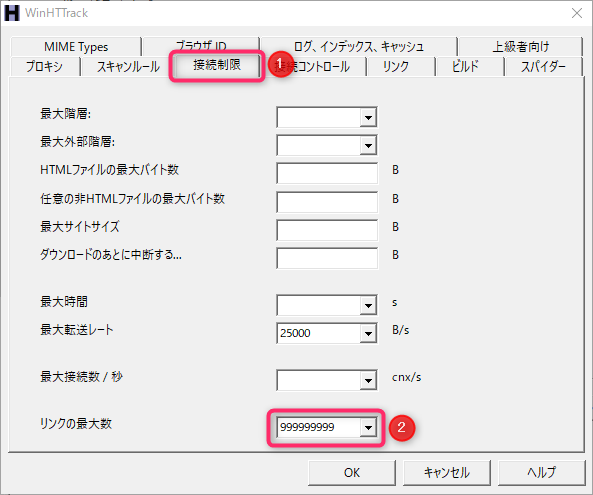
- 「リンクの最大数」を999999999に指定
※「リンクの最大数」の内容が空だと、何故かリンク数100000が上限となってしまう様です - robots.txt の指定を無視して取得する
※この設定をしないと取得出来ない所が出てしまう模様
手順
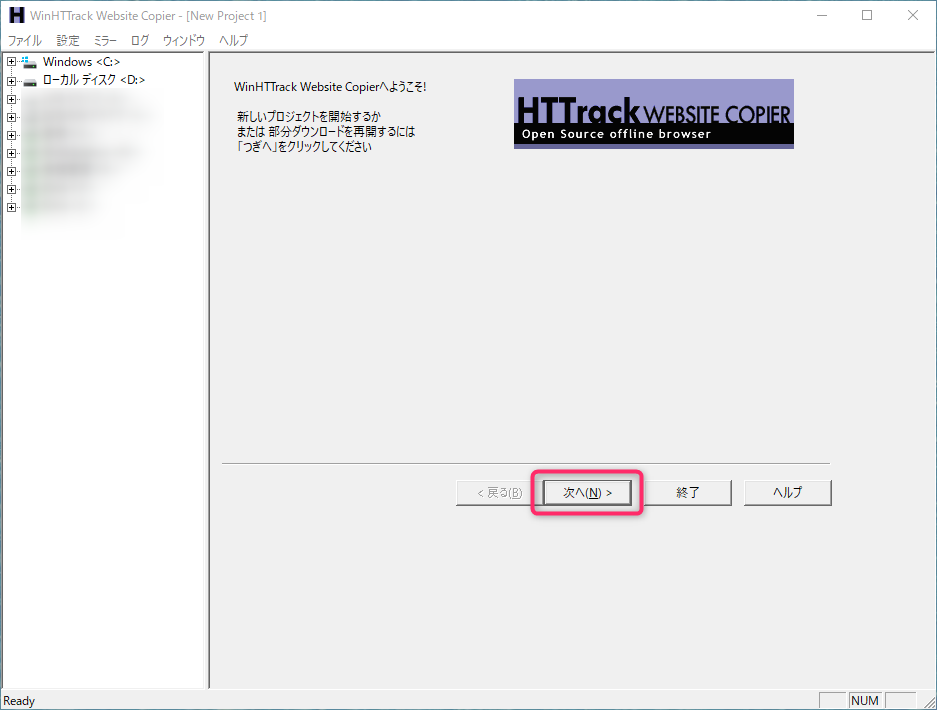
HTTrack(WinHTTrack)を起動すると、以下の様な画面が出るので「次へ」ボタンを選択
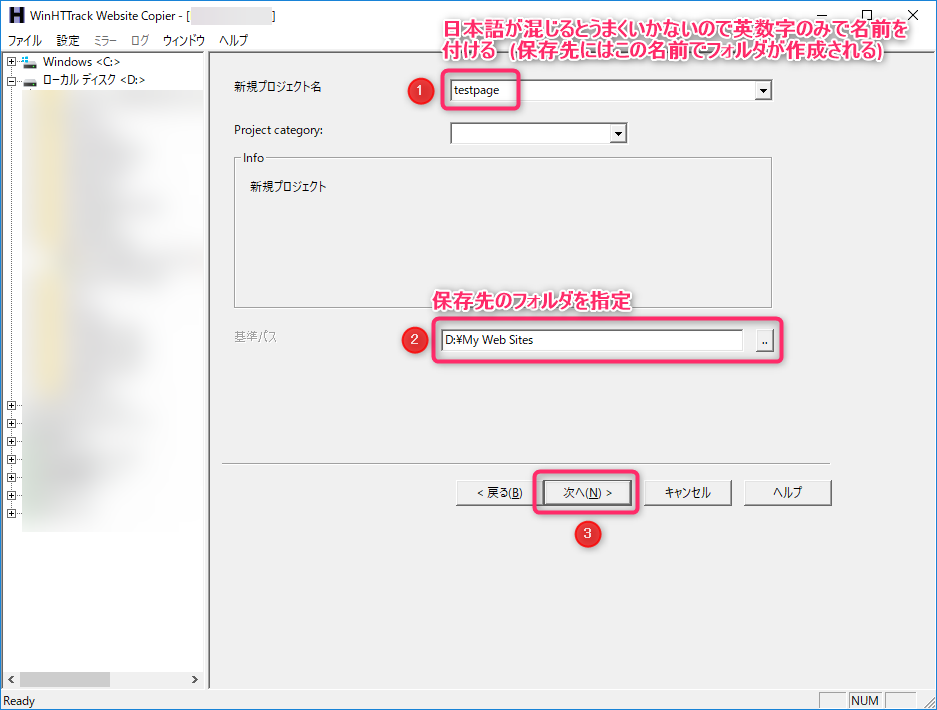
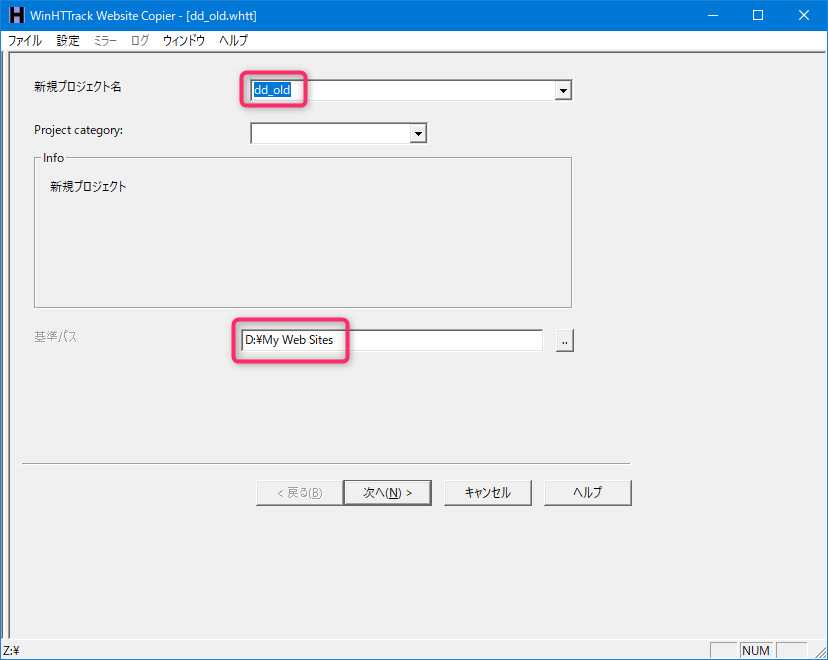
新規プロジェクト名・基準パス(保存先のフォルダ)を指定して「次へ」ボタンを選択
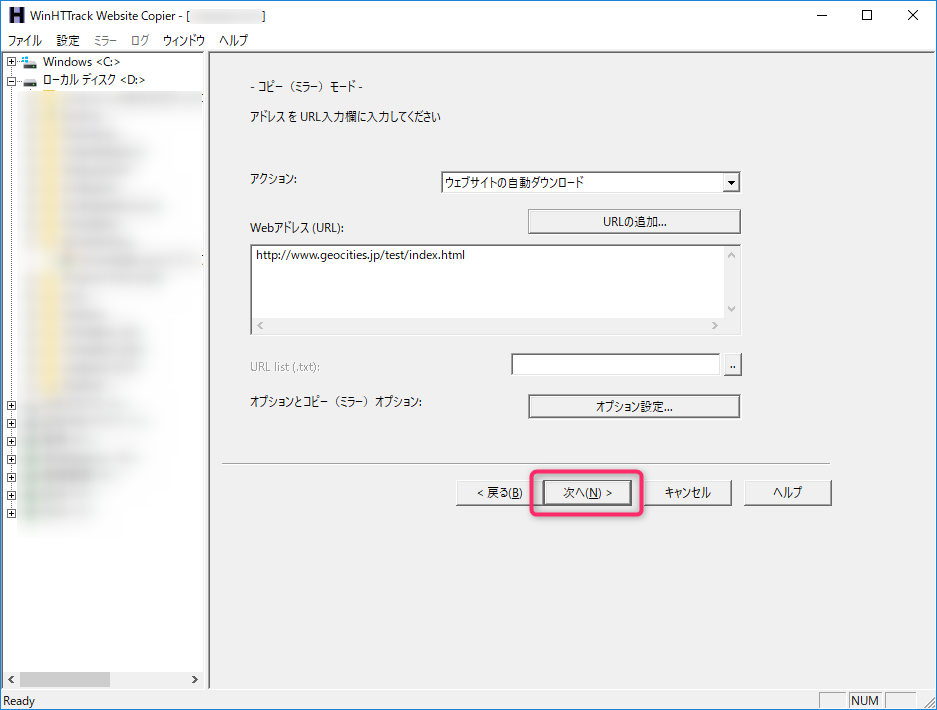
取得したいWebページのURLを指定して「オプション指定」ボタンを選択
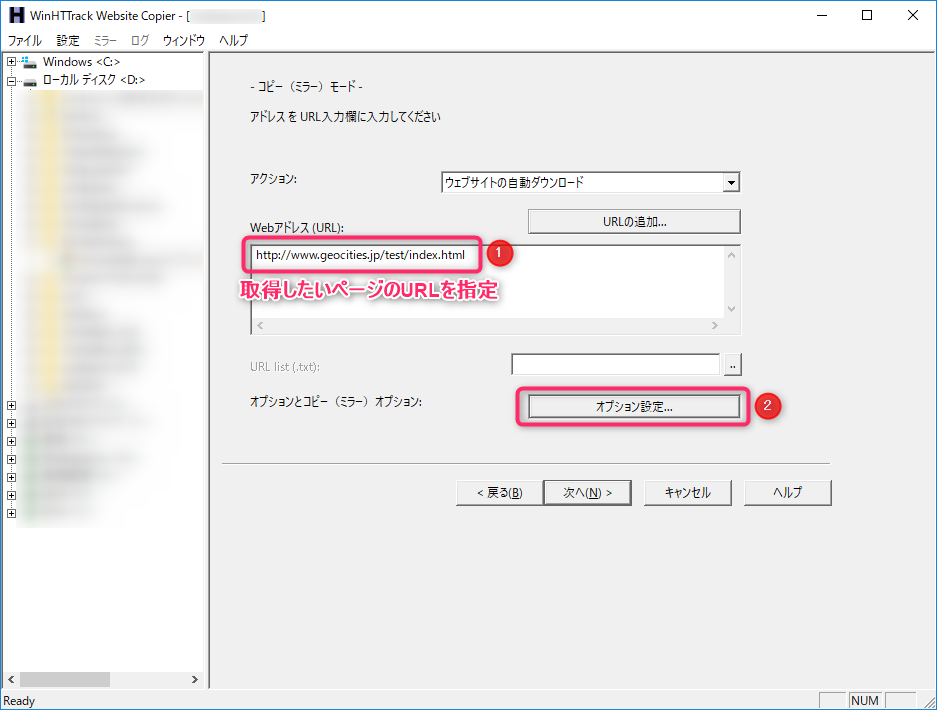
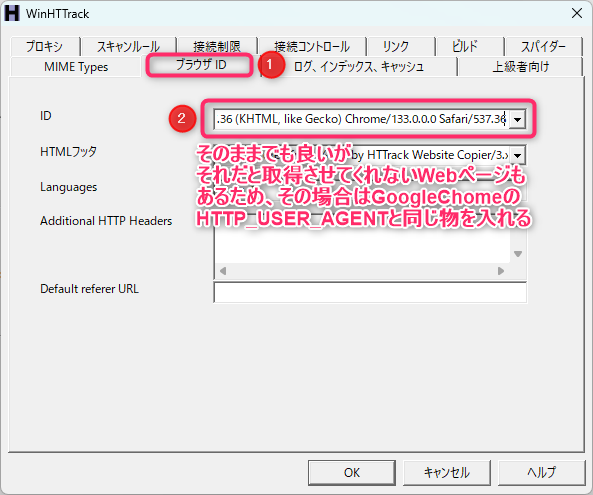
IDは最初に入っている物そのままでも良いが
それだと取得させてくれないWebページもあるため、その場合はGoogleChromeのHTTP_USER_AGENTと同じものを入れる
Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/133.0.0.0 Safari/537.36
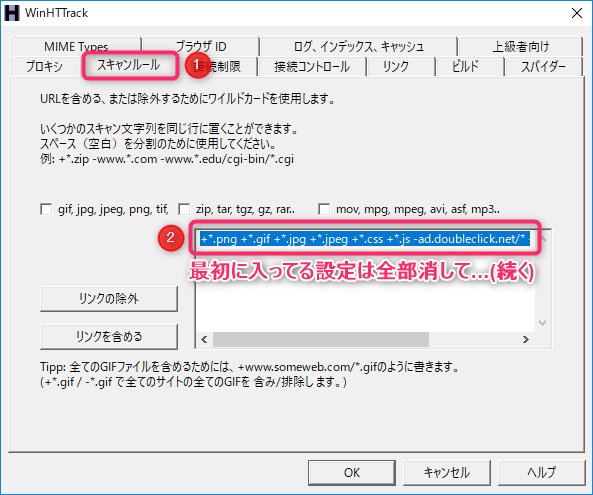
「スキャンルール」タブ→最初に入ってる設定は全部消して…
以下のフォーマットで、トップフォルダを含むURLを指定する
※ここで入力するURLにhttp://やhttps://は付けない
-* +【トップフォルダーを含んだURL】* 例①
-* +www.geocities.jp/test/*例②
-* +www.geocities.co.jp/SiliconValley/9988/*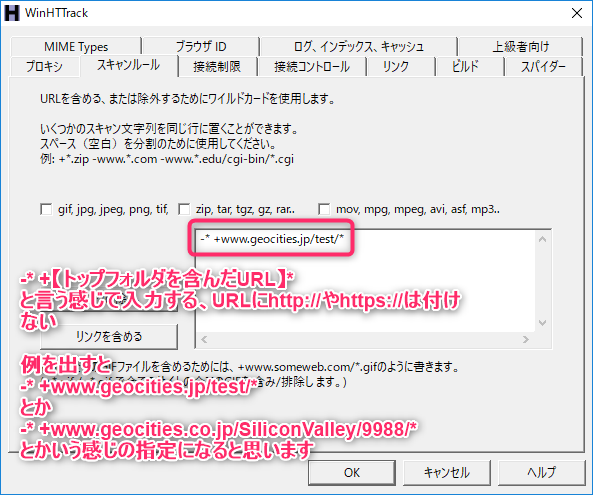
「接続制限」タブ→「リンクの最大数」を「999999999」に設定する
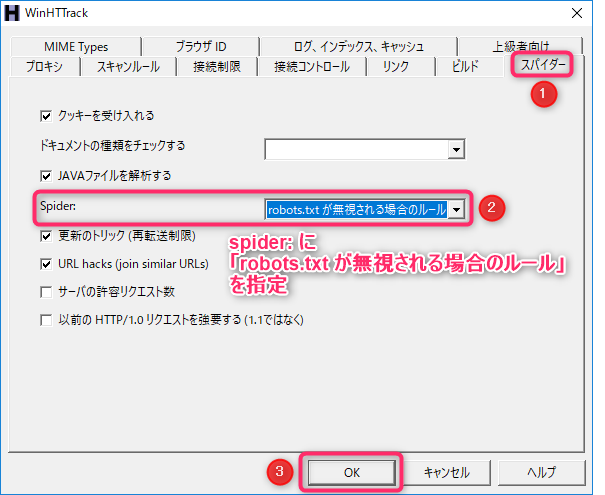
「スパイダー」タブ→「Spider:」を「robots.txt が無視される場合のルール」に設定→「OK」ボタンを選択
「次へ」ボタンを選択
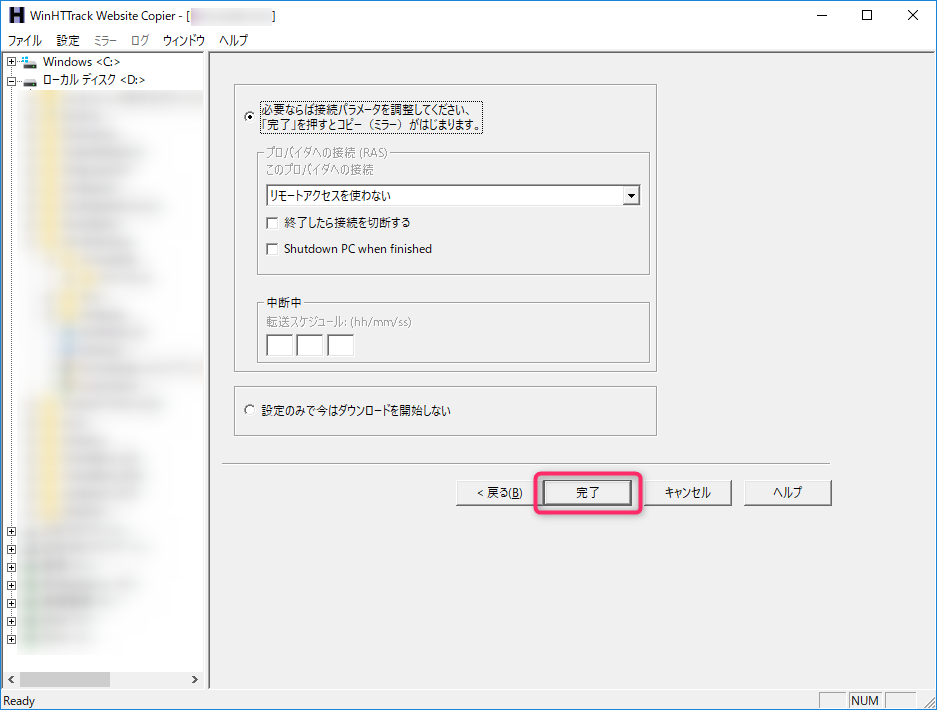
「完了」ボタンを選択
取得が始まりますので、終わるまで待ちます
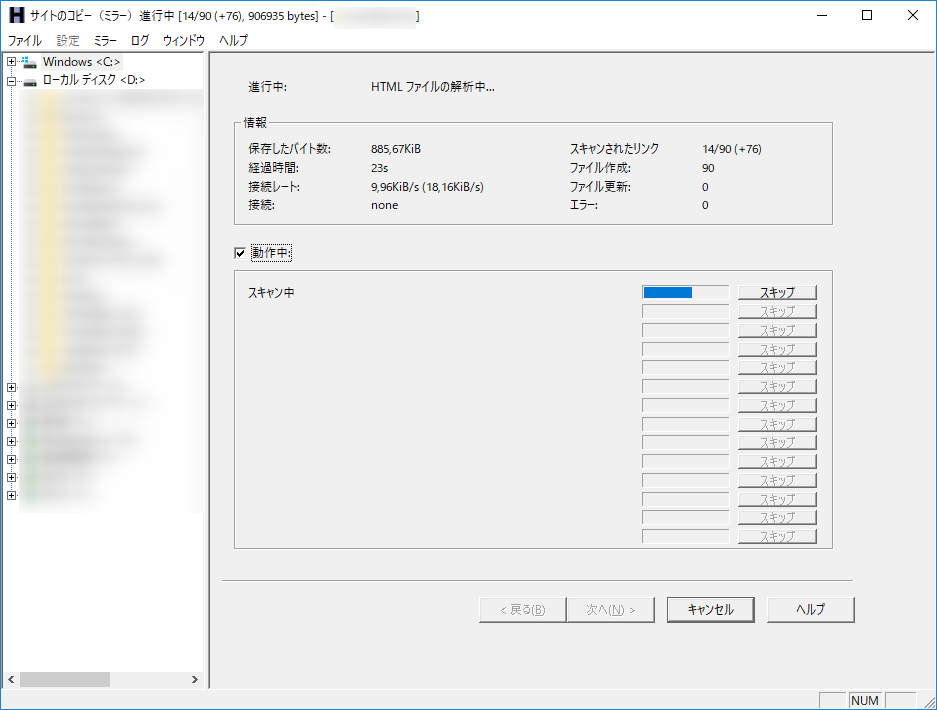
「コピー(ミラー)は完了しました」と出れば完了です
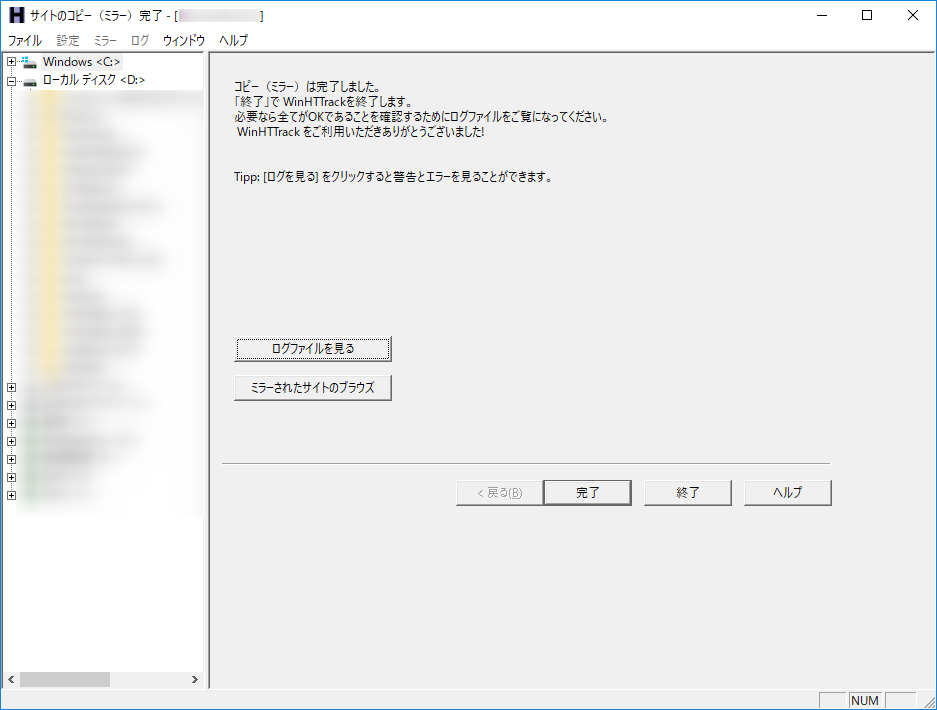
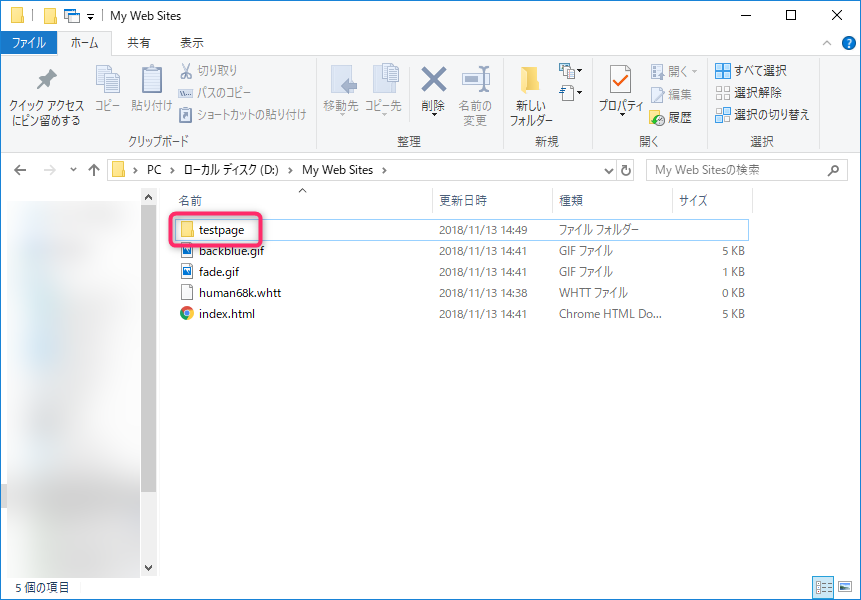
基準パス(保存先のフォルダ)に、新規プロジェクト名の名前でフォルダが作成され、この中に取得したサイトのWebデータが入ります
私の保管方法
以下は私の保管方法なので、他の人は参考にしなくても良いです
この新規プロジェクト名のフォルダのみを他の場所に移して保管、その際分かりやすい様にサイト名と年月日が入ったフォルダ名に変更しています
他のファイル(backblue.gif・fade.gif・index.html・???.whttとか色々)は、私は不要なので削除しています
ここにあるファイルは、HTTrackで複数のサイトを保管・管理や、再取得するために必要な物なのですが、私としては毎回丸っとWebサイトのデータが取れれば良いので
スキャンルールのおまけ話①
今回はGeositiesだけにあるファイルを取り込もうと思ったので
-* +【トップフォルダーを含んだURL】*-* +www.geocities.jp/test/*-* +www.geocities.co.jp/SiliconValley/9988/*というフォーマットにしましたが、もうちょっと再現性を高めようと思ったら
デフォルト設定されてるスキャンルールと合わせて
-* +*.png +*.gif +*.jpg +*.jpeg +*.css +*.js +【トップフォルダーを含んだURL】* -ad.doubleclick.net/* -mime:application/foobar-* +*.png +*.gif +*.jpg +*.jpeg +*.css +*.js +www.geocities.jp/test/* -ad.doubleclick.net/* -mime:application/foobar-* +*.png +*.gif +*.jpg +*.jpeg +*.css +*.js +www.geocities.co.jp/SiliconValley/9988/* -ad.doubleclick.net/* -mime:application/foobarとかでも良いと思います、サイトによってはより再現性が高まる…かもしれません(私はこの設定でやってないので曖昧表現)
スキャンルールのおまけ話②(Yahoo!ブログ)
Yahoo!ブログでは画像が以下の3つのドメインに点在しており、この画像が取得できる事が最低条件となります
- blogs.yahoo.co.jp
- blogs.c.yimg.jp
- blog-001.west.edge.storage-yahoo.jp
しかしHTTrackを使うとhtmlファイルが異常増殖したり、一部のhtmlファイルの拡張子がtxtに(00000.html.txt とか) なったりと問題が起きるため、断念しました
HTTrackを使う事を諦め、別のアプリ「ホームページクローン作成」を使う事で上手くサルベージできました、画像も問題なく取得できている様です
ホームページクローン作成の詳細情報 : Vector ソフトを探す!
スキャンルールのおまけ話③(旧D&Dサイト・dd_old)
なんか古いD&Dの記事が無くなるので保存した方が良いという記事を見つける
手動でやるのがしんどいので、HTTrackでざくっとダウンロードしてしまおうと思う
これで成功する保証はしないし、ダウンロード容量もどんな事になるかの保証もしない、確認もしんどいので…【自己責任でお願いします】
以下やった設定を書いておく
新規プロジェクト名
dd_old
[次へ(N)>]
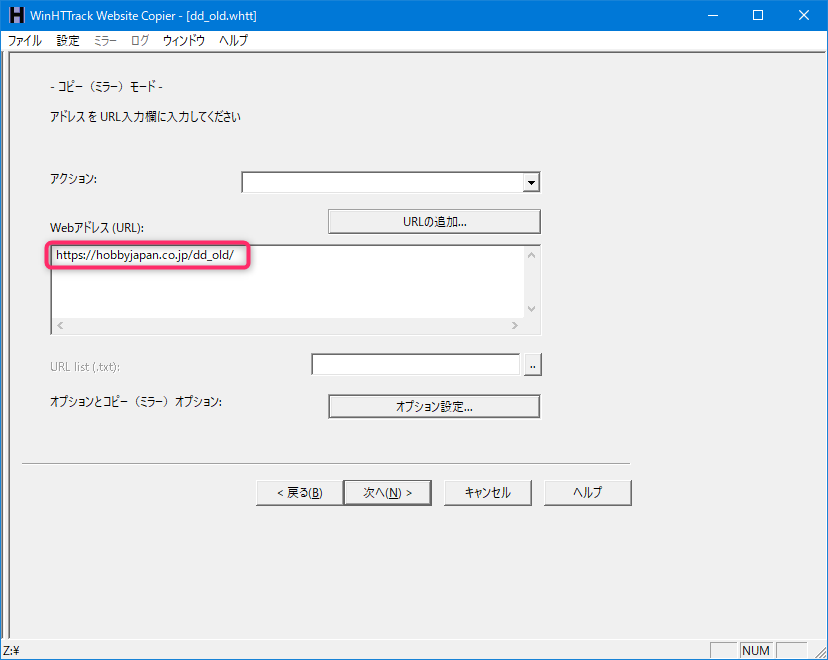
Webアドレス(URL):
https://hobbyjapan.co.jp/dd_old/
[オプション設定…]
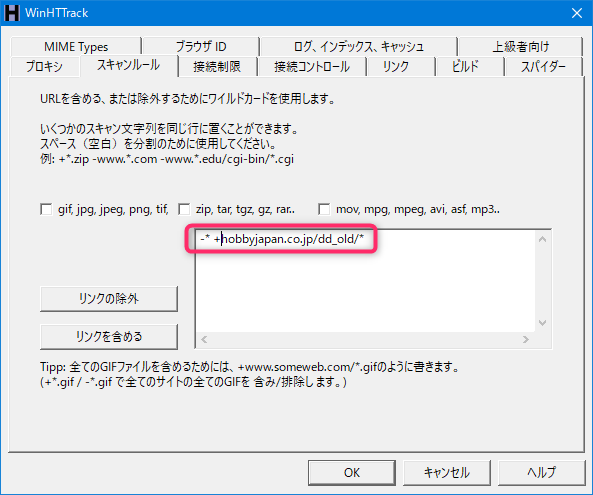
[スキャンルール]タブ
-* +hobbyjapan.co.jp/dd_old/*
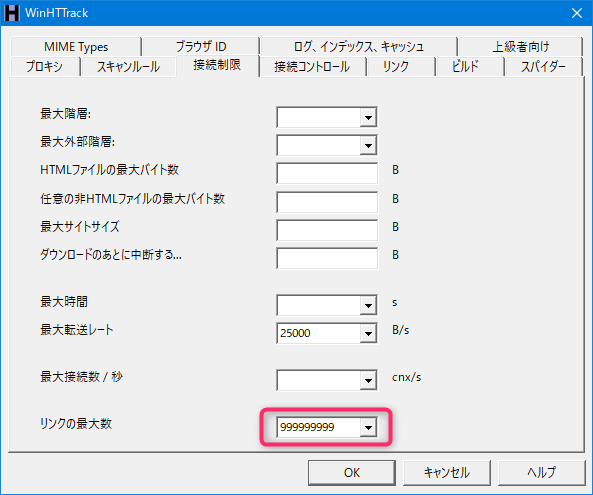
[接続制限]タブ
リンクの最大数
999999999
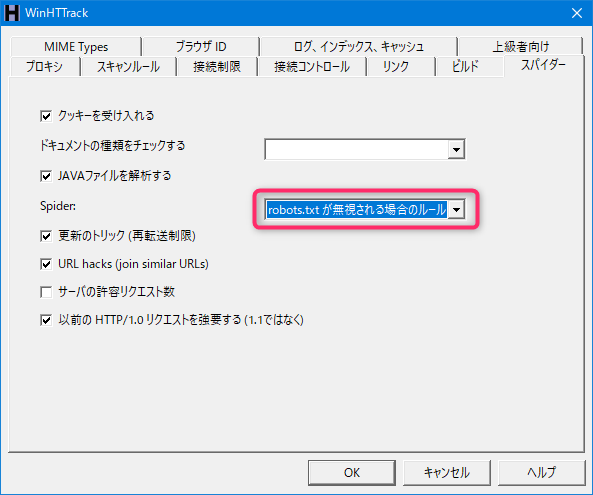
[スパイダー]タブ
Spider:
robots.txtが無視される場合のルール
[OK]
[次へ(N)>]
[完了]
→ダウンロードが完了するまで待つ
完了すると「コピー(ミラー)は完了しました。」と出る
スキャンルールのおまけ話④(Vectorホームページ・hp.vector.co.jp)
参考Webページ
- HTTrack Website Copier - Free Software Offline Browser (GNU GPL)
- HTTrack - Wikipedia
- ウェブサイトを丸ごと保存するHTTrack - Qiita
- のんびりライフ サイトダウンロードツールを利用してのオフライン閲覧 - ホームページクローンとHTTrack
- 作成されるファイル
- Yahoo!ブログからはてなブログに移行した後の、ご自身がYahoo!ブログにアップロードした画像データのインポートの手順が不要になります - はてなブログ開発ブログ
- Re: Too many URLs, giving up..(>100000) - HTTrack Website Copier Forum
トラックバック URL
https://moondoldo.com/wordpress/wp-trackback.php?p=3394