目次
検証環境
- Windows 11 Pro (21H2)
- Windows 11 Pro (24H2) (2025/3/1追記)
- ScanSnap Home 2.22.2.1 (2025/3/1追記)
- ScanSnap Organizer V5.6L42
- ScanSnap iX500
ScanSnap Home で使えるPDFに変換
ScanSnapでスキャンしたPDFであっても、PDF編集ソフトでいじった際にヘッダが変わってしまうと「検索可能なコンテンツに変換」の機能が「Scansnapでスキャンした画像ではないため、処理できません。」と出て使えなくなります
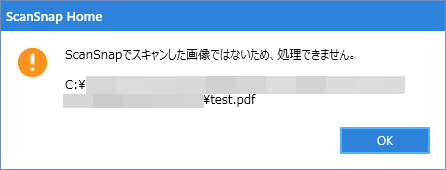
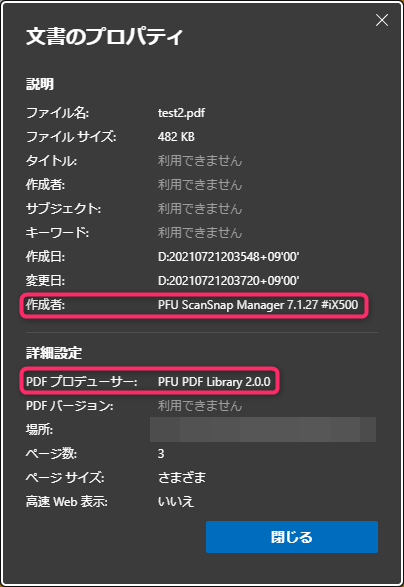
スキャンしたPDFには以下の様なメタデータが付いています
(アプリケーションによってメタデータの項目名が多少違います、以下Edgeの場合)
つまり、このメタデータを再度付けてあげれば良いのです
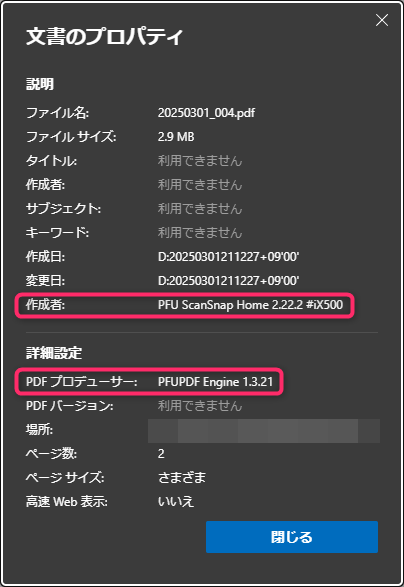
PDFに上記のメタデータを入れるバッチファイルを用意しましたのでお使いください
解凍して出てきた「PdfScanSnap.bat」と「exiftool.exe」を同じ場所に置き、「PdfScanSnap.bat」に変換したいPDFをドラッグ&ドロップすれば変換されます
仕様としてファイル名に以下の文字が入っていると変換できません(exiftoolの仕様です)
―ソЫⅨ噂浬欺圭構蚕十申曾箪貼能表暴予禄兔喀媾彌拿杤歃濬畚秉綵臀藹觸軆鐔饅鷭纊犾偆砡私はこれを「ScanSnap Home」に登録して使ってます

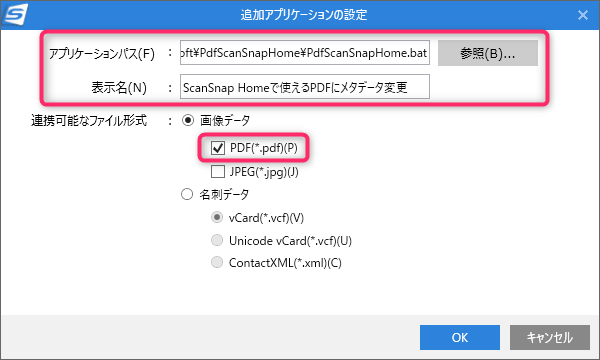
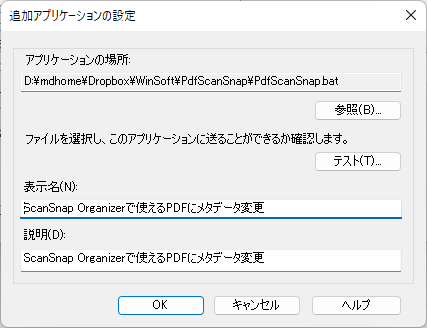
ScanSnap Organizer で使えるPDFに変換
ScanSnapでスキャンしたPDFであっても、PDF編集ソフトでいじった際にヘッダが変わってしまうと「検索可能なPDFに変換」の機能が「Scansnapで読み取ったPDF ファイルではないため、処理できません。」と出て使えなくなります
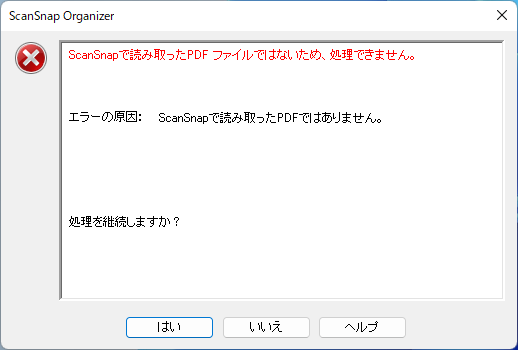
スキャンしたPDFには以下の様なメタデータが付いています
(アプリケーションによってメタデータの項目名が多少違います、以下Edgeの場合)
つまり、このメタデータを再度付けてあげれば良いのです
PDFに上記のメタデータを入れるバッチファイルを用意しましたのでお使いください
解凍して出てきた「PdfScanSnap.bat」と「exiftool.exe」を同じ場所に置き、「PdfScanSnap.bat」に変換したいPDFをドラッグ&ドロップすれば変換されます
仕様としてファイル名に以下の文字が入っていると変換できません(exiftoolの仕様です)
―ソЫⅨ噂浬欺圭構蚕十申曾箪貼能表暴予禄兔喀媾彌拿杤歃濬畚秉綵臀藹觸軆鐔饅鷭纊犾偆砡私はこれを「ScanSnap Organizer」に登録して使ってます
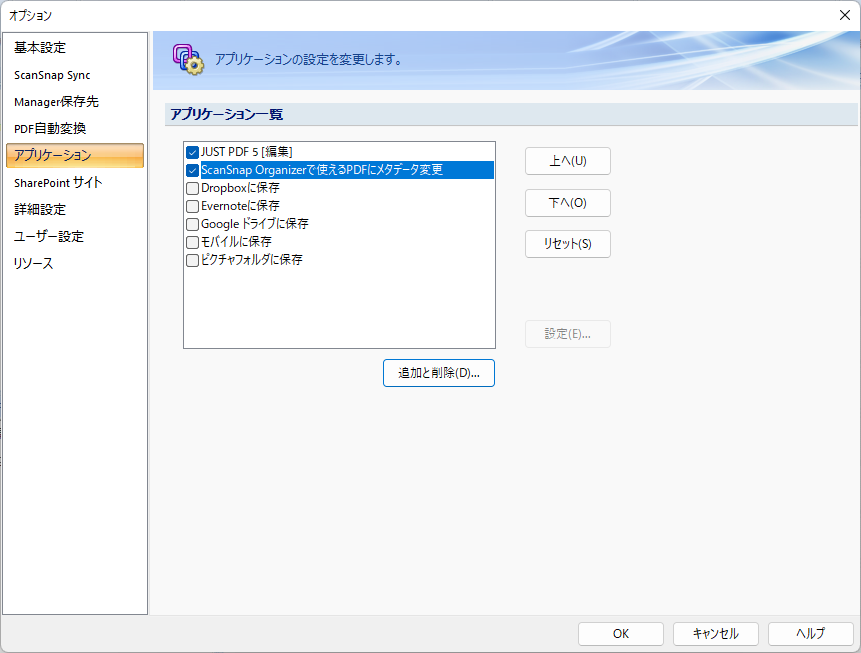
バッチファイルの内容を解説
以下は技術的な話なので、一般の方は見なくても大丈夫です
バッチファイルはexiftoolを使ってPDFファイルのメタデータ変更を行っています
まず以下のサイトでexiftoolのWindows版がダウンロードできます
「exiftool-12.45.zip」がダウンロード出来ます(時期によってバージョン上がり、ファイル名微妙に変わるかも?)
展開すると「exiftool(-k).exe」ファイルが出て来るので、ファイル名を「exiftool.exe」に直します
その「exiftool.exe」を使い、PDFを以下のコマンドで変換します
ScanSnap Home の場合
exiftool.exe -creator="PFU ScanSnap Home 2.22.2 #iX500" -Producer="PFUPDF Engine 1.3.21" (変換するPDFのフルパスファイル名)ScanSnap Organizer の場合
exiftool.exe -creator="PFU ScanSnap Organizer 5.6.42 #iX500" -Producer="PFU PDF Library 1.4.1" (変換するPDFのフルパスファイル名)さらに複数ファイルのドラッグ&ドロップに対応するために
バッチファイルの中身はこんな感じになっています
@echo off
cd /d %~dp0
for %%q in (%*) do (
echo %%q
exiftool.exe -creator="PFU ScanSnap Organizer 5.6.42 #iX500" -Producer="PFU PDF Library 1.4.1" %%q
)exiftoolはファイル名のUnicode対応がされておらず、そのせいで相性の悪い日本語ファイル名(いわゆるダメ文字)があります
その場合、PDFをアルファベットのみのファイル名に変えてから変換して下さい
現状分かっている相性の悪い文字はこちら
文字の中に「\」と同じコードが含まれているので、exiftoolがパス区切りと勘違いするのが原因と思われます
―ソЫⅨ噂浬欺圭構蚕十申曾箪貼能表暴予禄兔喀媾彌拿杤歃濬畚秉綵臀藹觸軆鐔饅鷭纊犾偆砡
トラックバック URL
https://moondoldo.com/wordpress/wp-trackback.php?p=8135